Introduction to Embeddings
Embeddings play a crucial role in natural language processing (NLP) and text analysis. Simply put, word embeddings represent words or phrases as vectors, which are lists of numbers. These vectors help encode the meaning of words so that similar words or phrases have closer vector representations. For example, the sentences "The cat quickly climbed the tree" and "The feline swiftly ascended the tree" have different words but similar meanings. Embeddings allow us to capture this similarity in meaning by placing these phrases close together in the embedding space. Embeddings make it more efficient to perform machine learning on large batches of text. By translating high-dimensional data (text) into a lower-dimensional space (vectors), embeddings efficiently capture the semantics/meaning of inputs, which can be useful for tasks such as text search.
An Example
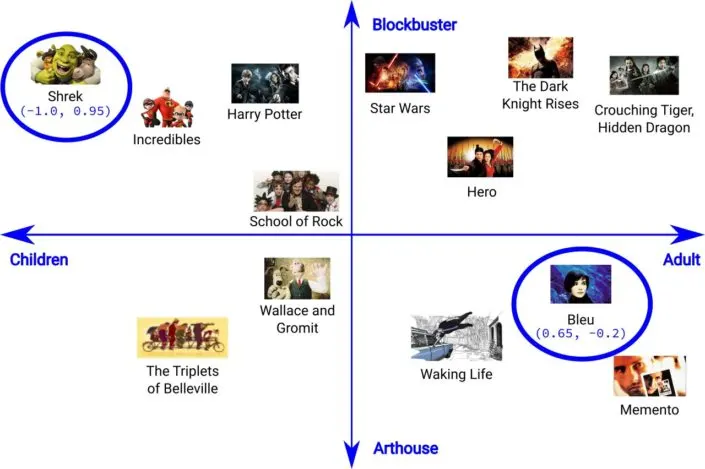
Let's consider a simple example of using vectors to cluster movies based on their characteristics. Imagine arranging a set of movies on a one-dimensional number line, where movies that are more closely related are placed closer together. This arrangement might represent movies based on their appeal to different age groups, such as children versus adults. -1 would represent a children's movie and 1 would represent an adult movie. Each movie could be given a score based on its audience's age group.
However, there are other aspects, like genre, that can also contribute to the similarity between movies. To capture this, we can extend the arrangement to a two-dimensional space, where one dimension represents the age group and the other represents the genre. For instance, a movie could be represented as a vector (0.3, 0.2), where 0.3 corresponds to the age group, and 0.2 corresponds to the genre. This embedding helps us identify and group movies based on their appeal to different age groups and genres.
Generalising to Higher Dimensions
As we've seen with the simple movie clustering example, we can represent data points in multi-dimensional spaces to capture various characteristics. The same concept can be applied to more complex data, such as geographical locations or even natural language text.
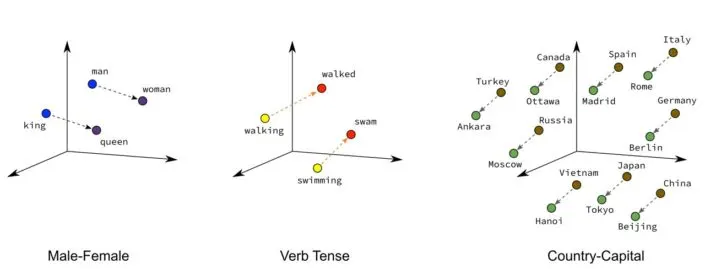
In the image above, capital cities are positioned close to their respective countries. In this space, not only are capital cities near their countries, but similar countries are also close to one another but along a different dimension. This arrangement effectively captures the relationships between countries and their capitals.
Generalising this concept to even higher dimensions allows us to represent more complex information, such as text. In this case, each dimension represents a different concept or aspect of the text, which enables us to encode an entire paragraph or a block of text as a single vector. By representing text in this manner, we can capture the underlying semantic meaning and relationships between words, phrases, or even entire paragraphs.
Using Vectors
To determine if two vectors are close to one another, we can use the cosine similarity. The cosine similarity measures the cosine of the angle between the two vectors, resulting in a value between -1 and 1. A value closer to 1 indicates a higher similarity, while a value closer to -1 indicates a lower similarity.
One example of using vectors in text analysis is classifying reviews as positive or negative. In this case, we can represent each review as a vector and train a machine learning model to classify them based on their vector representations. The model could learn to classify reviews as positive or negative based on the similarity between the review vectors and vectors representing positive or negative sentiment.
Another example is searching within a large body of text. In this scenario, we can break the text into smaller chunks or segments, each represented as a vector. When a user submits a search query, we convert the query into a vector in the same embedding space. To find the most relevant match, we measure the similarity between the search query vector and the vectors representing the chunks of text using cosine similarity. The chunk with the highest similarity to the search query vector is considered the best match for the user's query.
Trying it out
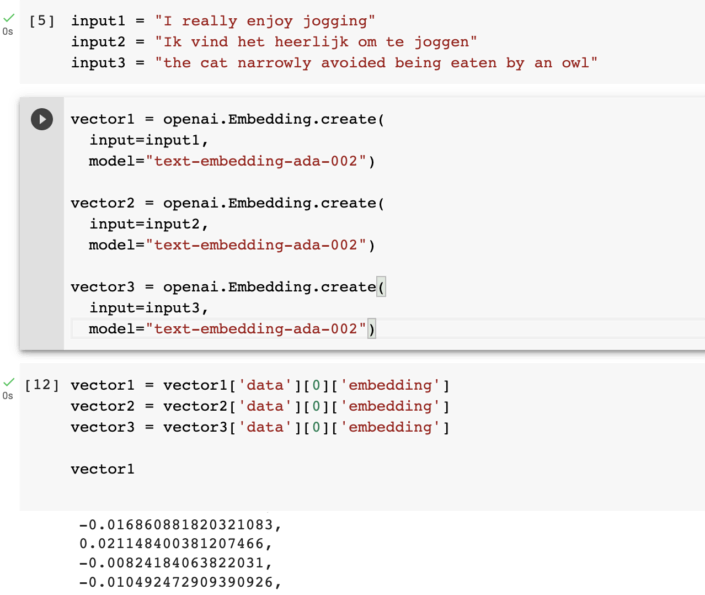
Generating or computing word vectors involves training a machine learning model on a large corpus of text. The model learns to represent words or phrases as vectors based on the context in which they appear, capturing semantic meaning and relationships between words. Take a look at this example of 3 vectors constructed using the OpenAI Ada-2 model (input 2 says "I really like running" in Dutch).
When we compute the cosine similarity between them this is what we get;

The two sentences about running are very close together, even though the languages are different. The cat sentence is farther apart. Now look at what happens if we compare the sentence "I enjoy jogging" with "I do not enjoy jogging".
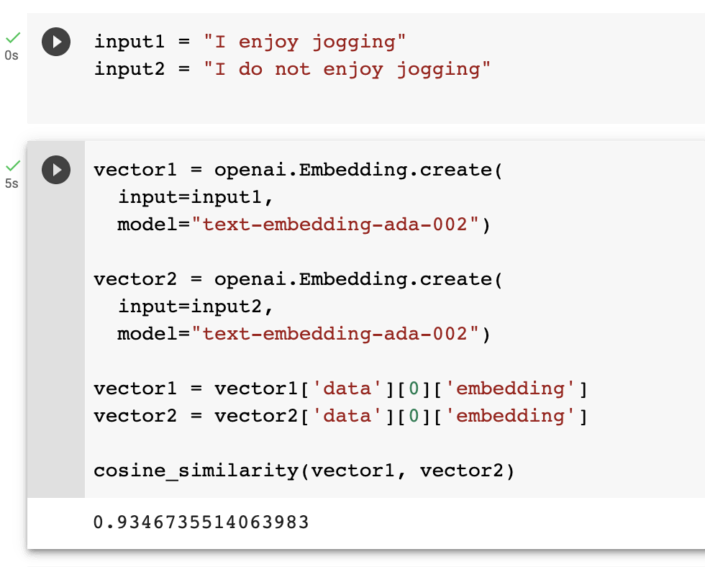
They are really close together! Closer than the English – Dutch pair. Can you figure out why?
Conclusion
In this article we have learned what embeddings are, and seen how they can be used for various natural language processing tasks. If you found this interesting you can read more in depth here or here.
← Back to all posts